* Failover Cluster
클러스터는 높은 수준의 가용성, 안정성, 확장성을 제공하기 위해 하나의 시스템을 이용하는 것보다, 두 개 또는 그 이상의 시스템을 이용한다.
장애를 수용하는 기능으로 클러스터는 고가용성에 대한 요구사항을 충족시켜준다. 이는 예상치 못한 서비스 중단을 감소시키고, 사용자에게 높은 서비스 이용률을 제공해준다.
클러스터 기술은 아래와 같이 세 가지 유형의 장애를 대비한다.
① 애플리케이션과 서비스 장애 : 애플리케이션과 필수 서비스에 영향을 미치는 경우
② 시스템과 하드웨어 장애 : 하드웨어를 구성하는 CPU, Drives, Memory, Network Adapters등에 영향을 미치는 경우
③ 여러기관의 사이트 장애 : 자연재해, 정전, 연결 중단 등으로 발생할 수 있다.
* Server Cluster
서버 클러스터는 각기 다른 서버(Enterprise or Datacenter)들을 하나로 묶어서 하나의 시스템같이 동작하게 함으로써, 클라이언트들에게 고가용성의 서비스를 제공하는 것을 말한다. 클러스터로 묶인 한 시스템에 장애가 발생하면, 정보의 제공 포인트는 클러스터로 묶인 정상적인 서버로 이동한다. 서버 클러스터는 사용자로 하여금 서버 기반 정보를 지속적이고, 끊기지 않게 제공받을 수 있게 한다.
* Server Cluster의 구성
- Single quorum device cluster 표준 쿼럼 클러스터
- Majority node set cluster
- Local quorum cluster 싱글 노드 클러스터
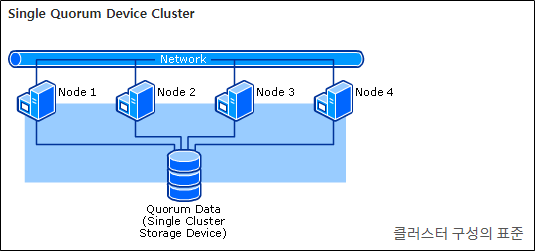
Quorum : 클러스터의 구성에 필수적인 항목 or 정책, 예를 들어 Quorum Disk 3이라고 한다면, Disk array에 5개의 Disk 중 3개가 무조건 활성화 상태여야만 클러스터가 정상 동작중이라고 할 수 있다.
Quorum Data를 보관과점에서 보면 cluster 구성을 갖고 있는 Disk Array(DB)를 하나로 구성할지, 여러 개로 구성할지 등으로 구분될 수 있다. 대다수의 시스템이 single quorum data 방식을 따른다.
* CSV(Cluster Shared Volume 클러스터 공유 볼륨)
한 마디로 공유 디스크이다. 동시에 여러 컴퓨터가 디스크의 소유권을 가지고 사용할 수 있는 상태를 말하는 것이다.
* CSV를 사용하는 이유
CSV는 여러 노드에서 동시에 단일 공유 저장소 볼륨에 액세스 할 수 있도록 하여 가상 컴퓨터의 가용성 및 관리 효율성을 높일 수 있다.
ex) CSV를 사용하는 장애 조치 클러스터에서는 파일이 저장소의 단일 디스크(LUN)에 있는 경우에도 여러 클러스터 노드에 분산된 여러 클러스터 된 가상 컴퓨터에서 가상 하드 디스크 파일에 동시에 액세스 할 수 있다. 이는 클러스터 된 가상 컴퓨터가 단일 LUN만 사용하는 경우에도 독립적으로 장애 조치할 수 있음을 의미한다.
장애 조치 클러스터 노드 간에 Hyper-V 가상 컴퓨터의 실시간 마이그레이션도 지원한다.
* Failover Cluster의 예시 1 (기초)
만약에 롤 서버가 한개라고 가정을 했을 때 우리가 게임을 하다가 서버가 망가지거나 꺼져버리면 게임이 안될 것이다. 근데 서버를 두 개 사용하고 이중화를 구성하면 한쪽이 꺼지더라도 다른 한쪽이 데이터를 백업해서 운영을 하기 때문에 우리는 한 서버가 꺼지더라도 인지하지 못하고 그냥 즐겁게(?) 게임을 할 것이다.
* Failover Cluster의 예시 2 (심화)
(클라이언트, 가상 서버, DHCP 서버(위에는 1, 밑에는 2), ST는 스토리지라고 가정하고 진행합니다.)
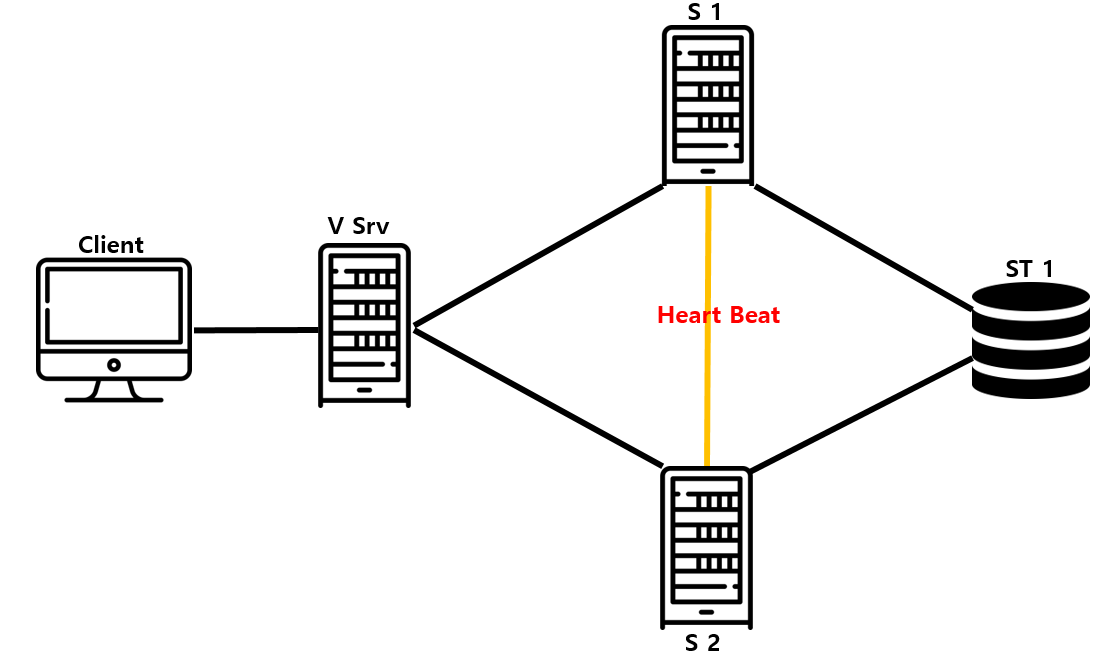
먼저 DHCP 서버를 운영하기 위해서 두 개의 서버가 공통으로 이용하는 하나의 스토리지(할당할 IP 범위, 이미 할당 한 IP 주소들의 정보가 저장됨)가 필요하다. 처음 1번 서버가 DHCP를 운영하고 있고, 클라이언트는 1번 서버에게 IP를 받고 있는데 1번 DHCP 서버에 장애가 발생하면 Heart Beat 통신(그림에 보이는 Heart Beat는 1번과 2번이 서로 상대방 서버가 장애가 발생했는지 확인하기 위해 서로 주고받는 메시지이다. Heart Beat통신을 하는 케이블이 따로 더 필요함)이 안 되는 것을 2번 서버가 확인하고 스토리지에 저장된 데이터를 백업해서 이어받아 DHCP 서버 역할을 하게 된다.
# DHCP를 예로 들었지만 윈도우 서버의 경우에는 DHCP 장애 조치에 별도의 Storage가 필요하지 않고 IP 주소 임대 데이터가 각 서버에 연속적으로 복제된다.
# 클라이언트가 실제 서버의 주소를 알고있으면 보안상에 문제가 있을 수 있기 때문에 가상 서버가 존재한다. 클라이언트는 가상 서버의 주소만 알고 있음! (이건 나중에 실습할 때 다시 설명하도록 하겠습니다!)
# 여기서 Failover Cluster는 확인하고 다시 백업하는 시간이 존재한다. 그것을 Down Time이라고 하는데 이 단점을 보완하기 위해 LB(Load Balancing)가 탄생하게 되었다.
+ LB 맛보기
로드 밸런싱도 추후에 포스팅하겠지만 잠깐 설명하고 넘어가도록 하겠다. 위에 말한 것처럼 Cluster는 한 서버가 죽으면 한 서버가 다시 받기까지의 Down Time이라는 게 존재한다. 하지만 로드 밸런싱은 두 개 이상의 서버가 한 번에 작동한다. 1번 서버도 운영하고 2번 서버도 부하 분산해서 운영. 그러면 1번 서버가 꺼져도 2번 서버는 아무 일 없는 둥 계속 운영하는 방식이라 Down Time이 존재하지 않기 때문에 Cluster보다 더 원활한 서비스 제공이 가능하다.
※ 고가용성(HA)을 위한 이중화 실습은 추후에 포스팅하도록 하겠습니다. (ex. DHCP, Hyper-V 등)
'IT Network System > Network' 카테고리의 다른 글
| Network Basic (1편 : Network란) (0) | 2021.01.28 |
|---|---|
| 왜 IP 주소, MAC 주소 두 개나 쓰는 걸까? (6) | 2021.01.28 |
| Web (개인 공부용) (0) | 2021.01.27 |
| Web Server와 WAS (0) | 2021.01.27 |
| iSCSI (0) | 2021.01.26 |


댓글